
Queue, Event or Webhook? 5 questions for your integration checklist
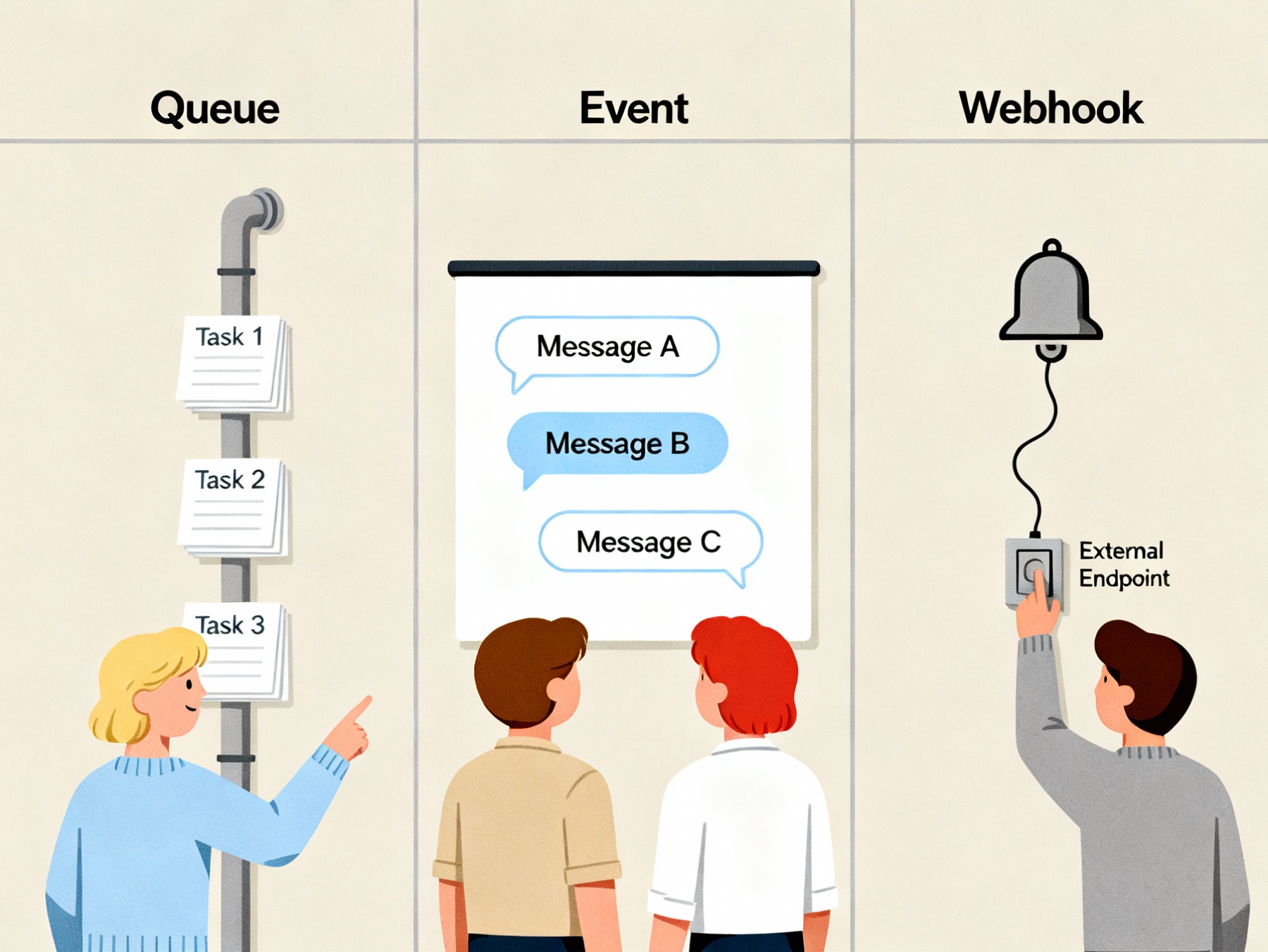
Choose a queue when something must be carried out exactly once and in the right order. Choose an event when several systems need to know something happened. Choose a webhook when an external party should get a simple nudge — and you can live with retries when needed.
Queue, event or webhook? 5 questions for your checklist
Choosing transport is really about responsibility and risk. Who promises what, to whom, and with what consequences if something is missed? Once that’s clear, the choice is rarely technically hard. Below are the three concepts in plain language, followed by a practical decision section and two concrete cases.
Three concepts — explained without tech-speak
Queue
Think “to-do list” where each task is picked up by a worker. Great when something must be executed (create order in ERP, generate invoice), when order matters, and when you want to pause, rate-limit, and drain a backlog.
A queue helps you smooth spikes and protect the receiver when inflow varies. You get natural metrics (how much is waiting, how fast it’s processed) and can replay without manual work. It costs a bit more to set up — but you gain control.
Event
A notice board where you pin “Order shipped”. Many can read the note; no one is forced to act — but multiple consumers can react (notify customer, update analytics, trigger returns policy). Perfect when “several receivers need to know.”
Events let you enable new consumers without touching the source system. You decouple and future-proof. Drawback: an event does not guarantee that something gets done; it’s a signal, not a work order.
Webhook
A doorbell: “Ping! Something happened.” You send an HTTP call to someone else’s endpoint. Fast and simple, but you don’t own the receiver’s operations. Good for ecosystems and partner integrations — if you plan for timeouts, retries, and duplicates.
Webhooks are excellent when you want to be easy to integrate with. Always include signatures, timestamps, and retries — the internet really is unreliable.
Decide correctly with 5 straight questions
Use the same few questions every time. It creates a stable habit so the team makes the same decision even when people change.
-
Must something be executed — or is it enough to know?
-
Must be executed ⇒ Queue (guaranteed handling, retries, backpressure).
-
Enough to know ⇒ Event (fan-out to many, loosely coupled architecture).
-
-
Do you have one or many receivers?
-
One receiver ⇒ Queue.
-
Several now — or likely later ⇒ Event (let more subscribe without changing the source).
-
-
Do you need ordering and exactly-once?
-
Yes ⇒ Queue (idempotency + ordering are easiest here).
-
No ⇒ Event or Webhook.
-
-
Do you own both sides or are you reaching a partner?
-
Your own ecosystem ⇒ Queue/Event internally.
-
External party ⇒ Webhook out, ideally with signing, retries, and dead-letter logic.
-
-
How sensitive is the receiver to load?
-
Sensitive / quota-limited ⇒ Queue in front of the receiver (throttling).
-
Can handle broadcast ⇒ Event; for externals, narrow via a gateway/webhook distributor.
-
The point isn’t to be 100% “right” from day one, but to avoid expensive mis-choices. You can change pattern later — but pick the one that best mirrors responsibility here and now.
Quick “if–then” guide (no table, just decisions)
Use the list in your backlog as small decision cards. It keeps you consistent even at high speed.
-
If an order must be created in the ERP → send to a queue.
-
If several teams want to react to “order shipped” → publish an event.
-
If a third party wants a ping when inventory changes → send a webhook (with signature + retries).
-
If you don’t know who the consumers will be in six months → choose events (future-proof).
-
If the receiver is often throttled by quotas → put a queue in front and drain at a safe pace.
-
If the same message sometimes gets sent twice → make the consumer idempotent (regardless of pattern).
Two concrete cases
Case A: Order → ERP
This requires execution, ordering, and error handling. Put the order on a queue. The consumer creates the order in the ERP, logs an acknowledgement, and on failure retries with backoff. If something jams, it lands in a dead-letter queue where you can “replay” without manual reconstruction.
Result: no duplicates, no lost orders, calmer support. In practice this cuts MTTR significantly during ERP incidents. You see exactly which orders are waiting, how far they got, and can re-run in a controlled way after an outage. Economically it means fewer manual touches and fewer customer compensations. Above all, it becomes predictable: even when something fails, you know the next step.
Case B: Inventory change → multiple channels
One change must reach the web, marketing, and a couple of partners. Publish an event InventoryUpdated. Internal systems subscribe directly. External partners are reached via a webhook distributor that receives the event, enforces quotas, signs requests, and handles retries.
Result: you add, switch, or pause consumers without touching the source system. You can roll out changes in stages too: add a new channel, validate in shadow mode, scale up when it behaves well. The event is your anchor — consumers evolve at their own pace without creating chain reactions.
The only bullet list: benefits when you choose the right pattern
-
Fewer production incidents: the right transport reduces duplicates, loss, and timeouts.
-
Shorter time to deliver: no ad-hoc fixes when new receivers appear.
-
Lower cost over time: events let you reuse the same signal for more purposes; queues cut manual rework.
-
Better partner experience: webhooks with signing and retries make collaboration smooth.
-
Measurability: queues/events give natural metrics for lead time, errors, and backpressure.
These benefits don’t come from “more tech,” but from clear responsibility. When everyone knows what is and isn’t guaranteed, much of the noise that steals time disappears.
Common pitfalls (and how to avoid them)
-
Webhook without retries. The network fails. Retry with backoff and timestamps.
-
Using events as obligation carriers. If something must happen, it’s not an event — it’s a task ⇒ put it on a queue.
-
“Everything in one webhook.” You become tightly coupled to the receiver’s SLA. Add a staging layer (queue/gateway) that buffers and signs.
-
No idempotency. Whatever the pattern: protect with unique keys (order ID, version) so duplicates do no harm.
-
Unclear responsibility. Write producer/consumer contracts in plain text: what is sent, when, how long retained, how acknowledged?
These mistakes feel “faster” in the moment. The bill arrives later as debugging and manual churn. Doing it right isn’t expensive — it’s discipline and a few standards.
Operational governance without busywork
Track three simple measures per flow: lead time (from signal to reaction), errors per 1,000 messages, and manual replays per week. If the numbers trend the right way, the pattern holds. If not — switch before you scale.
Keep the visualization threshold low: a simple dashboard is enough. What matters is change over time, not perfect numbers. Start with a baseline, follow up weekly, and link measurement to decisions — what do we stop doing when a number drops, and what do we invest in when it rises?
Integration checklist before you decide (short, practical)
-
What must happen, and what is “good to know”?
-
How many consumers exist today — and tomorrow?
-
Can the receiver handle spikes, or do we need to buffer/throttle?
-
What idempotency key will we use?
-
How will we measure lead time and errors?
Use the checklist in PR descriptions or ticket briefs. It takes seconds to fill in but saves hours later because the choice becomes traceable.
Summary
-
Queue = tasks that must be executed, with ordering, retries, and throttling.
-
Event = happenings that many can react to, without an execution obligation.
-
Webhook = a ping to externals, quick and simple — but build guardrails.
Choose pattern based on responsibility, receivers, and risk, not habit. Done right, you get fewer disruptions, faster change, and lower cost when you add new flows.
Read more
More blogs
All blogs
Agentic Commerce removes the human safety net. Weak data, fragile integrations and inconsistency become immediate business risk.
Read more
Agentic Commerce reshapes commerce so only companies with stable, traceable information flows stay visible in customers’ agent-driven journeys
Read more
Serverless Azure integrations: manage rules as config, launch flows without code and boost AI visibility while cutting order costs.
Read more